LyndaAi - Systems and Tooling
Case Study: AI Tooling and DevEx

System Context and Tooling Surface
This case study examines LyndaAI as a working AI-enabled system, with particular attention to how tooling, workflows, and process constraints shaped both developer experience and system behavior.
The frontend codebase is structured to support iterative, AI-assisted development rather than one-off feature delivery. This intent is visible not in a single abstraction layer, but across repository layout, documentation, automation hooks, and review workflows.
This work reflects the workflows and constraints of this project, not a generalized or organization-wide standard.

At a high level, the system is organized around the following concerns:
Application code (
src/)
The Next.js frontend implements user-facing functionality, real-time orchestration streams, and agenda-driven workflows. React components, Shadcn UI primitives, global styles, and tests are co-located to reinforce consistency and reviewability.Internal documentation (
docs/)
A substantial internal handbook defines AI development guidelines, contribution rules, CI/CD expectations, runtime safety practices, and integration contracts (e.g., backend endpoints, chat socket flow). These documents act as active constraints on how both humans and AI tools are expected to modify the system.Automation and validation tooling (
scripts/, npm scripts)
The repository exposes explicit automation entry points; such as configuration sync checks, linting, type checks, builds, and Storybook validation - designed to be invoked both locally and in CI. These scripts serve as guardrails that limit the blast radius of AI-assisted changes.Testing surfaces (
e2e/, Storybook, Jest, Playwright)
The system adopts a layered testing strategy, combining component stories, unit tests, and end-to-end flows. This creates multiple evaluation surfaces for AI-generated or AI-adjacent changes beyond simple output correctness.Workflow standardization artifacts (AGENTS.md, CONTRIBUTING.md, PR templates)
The repository encodes expectations for clean git state, small diffs, canary commits, conventional commit messages, and structured pull requests. These constraints are explicitly designed to make AI-assisted contributions reviewable, auditable, and reversible.
Rather than treating AI as an opaque subsystem, the codebase makes system behaviour legible after the fact through extensive logging, documented debugging workflows, and explicit audit trails embedded in chat history and orchestration metadata.
This section frames LyndaAI not as a finished platform, but as an environment in which questions about LLM behaviour, misuse patterns, coordination overhead, and safety tradeoffs could be observed under real development pressure. Subsequent sections examine how these structures influenced evaluation, failure handling, and day-to-day developer workflows.
Evaluation & Feedback Loops
Evaluation in LyndaAI extended beyond whether individual AI outputs were “correct.” The system exposed multiple feedback surfaces -runtime, test-time, and review-time - that together shaped how failures were detected, understood, and acted on.
Rather than relying on a single notion of correctness, the codebase makes evaluation distributed and layered, reflecting the reality that LLM-based systems often fail in ways that are partial, delayed, or context-dependent.
Runtime Feedback: Making Behaviour Observable
At runtime, the frontend includes extensive logging and diagnostic hooks across authentication, orchestration, and real-time transport layers.
Key characteristics of this layer include:
Transport-level visibility
WebSocket and SSE clients log connection lifecycle events, parse errors, ping timeouts, reconnect attempts, and exhaustion thresholds. These signals allow engineers to distinguish between network instability, orchestration downtime, and malformed AI outputs.Tool invocation diagnostics
Tool wrapper functions log request payloads (in non-production environments), backend validation errors, and fallback success paths. This makes it possible to diagnose whether failures originate in prompt construction, schema mismatch, or backend rejection.Environment-aware logging
Logging behaviour varies by environment (development vs. production/test), suppressing expected noise while preserving error visibility where it matters. This reflects an explicit tradeoff between observability and operational signal quality.
Runtime feedback is therefore designed not to guarantee correctness, but to make unexpected behaviour inspectable without halting the system.
Evaluation Beyond Output Correctness
The repository documentation repeatedly emphasizes that AI-assisted changes and AI-driven behaviour should be evaluated in context, not judged solely on surface-level results.
Examples of this broader evaluation posture include:
Canary commits and small diffs
AI-generated changes are expected to be introduced incrementally, enabling reviewers to assess intent, scope, and side effects rather than accepting large, opaque changes.Backend truth verification
Frontend contributors are instructed to log and inspect real backend responses before adapting mappings, explicitly guarding against AI hallucinations and stale assumptions during development.Fallback-aware behaviour
Certain API layers attempt alternate endpoints or degrade gracefully rather than failing immediately, shifting evaluation from “did this call succeed” to “did the system recover safely.”
In this context, correctness becomes one signal among many, alongside reversibility, diagnosability, and failure containment.
Test-Time Feedback as a Constraint Surface
Testing in LyndaAI functions less as a proof of correctness and more as a constraint system that bounds acceptable change.
The repository enforces:
Layered testing expectations
Unit tests, Storybook stories, Playwright end-to-end tests, and TypeScript checks all contribute distinct signals. A change that passes one layer but fails another is treated as incomplete rather than partially acceptable.CI parity requirements
Local validation commands are explicitly aligned with CI behaviour, reducing the risk that AI-assisted changes pass locally but fail in shared environments.Mandatory pre-PR validation
Contributors (human or AI-assisted) are required to run linting, tests, type checks, builds, and Storybook builds before opening a pull request. This shifts evaluation earlier in the workflow and reduces review-time ambiguity.
Tests here do not assert that AI behaviour is “right,” but that changes respect agreed-upon boundaries of stability, compatibility, and maintainability.


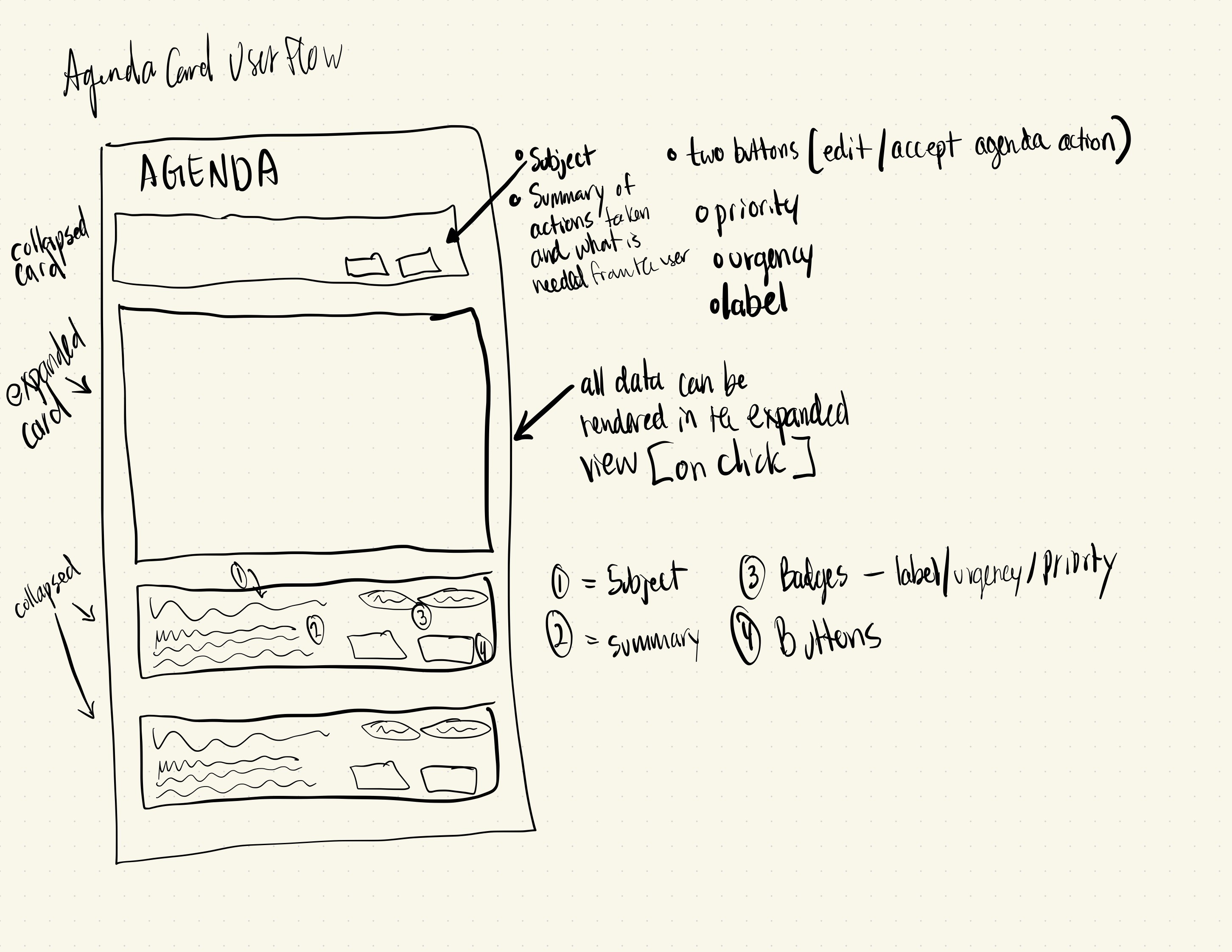

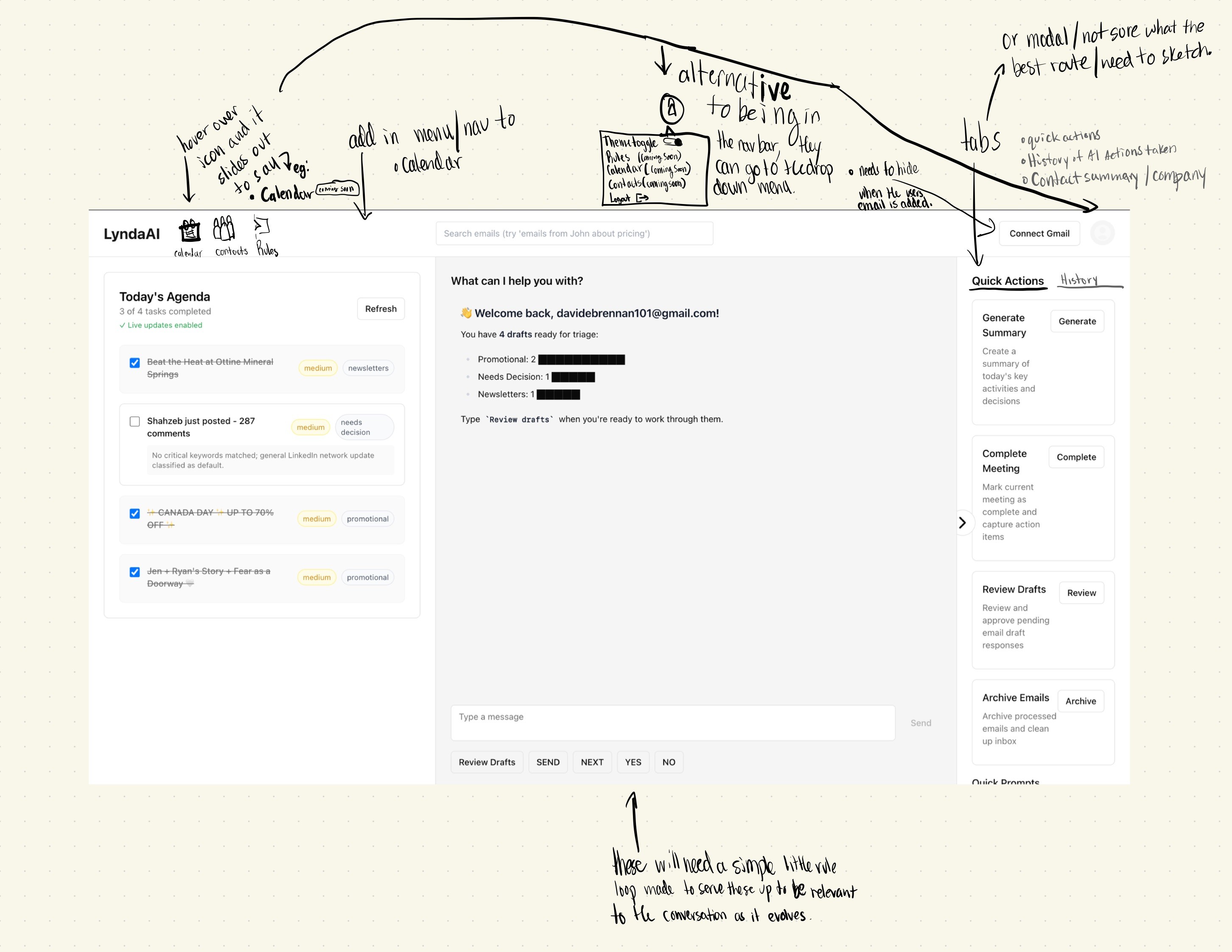
Review-Time Feedback and Human Judgment
Pull request review acts as the final evaluative surface, where automated signals are combined with human judgment.
Several structures reinforce this role:
Structured PR templates
Contributors must explicitly declare what changed, what was tested, and what remains unverified. This makes uncertainty visible rather than implicit.Commit history discipline
Conventional commit formatting and small diffs support reasoning about change intent over time, which is especially important when AI tools assist with code generation or refactoring.Merge-gated sequencing
Project plans and sprint artifacts indicate that workstreams are gated on successful merges, reinforcing evaluation as an ongoing process rather than a final checkpoint.
In aggregate, review-time evaluation serves as the place where automated signals are interpreted, contextualized, and sometimes overridden.
Summary: Evaluation as a System Property
Across runtime diagnostics, test constraints, and review discipline, evaluation in LyndaAI is treated as a system property, not a single mechanism.
The system does not assume AI behaviour can be fully validated upfront. Instead, it prioritizes:
early detection of unexpected behaviour
multiple, redundant feedback channels
explicit surfacing of uncertainty
human judgment at well-defined decision points
This posture reflects the practical reality of LLM-based systems: failures are often ambiguous, partial, and recoverable, and evaluation must be continuous rather than binary.
Failure Modes & Misuse Patterns
Building the LyndaAI frontend with AI-assisted tooling surfaced a set of failure modes that were developmental, not product-facing. These failures did not originate from the assistant’s behavior for users, but from the interaction between AI tools, human contributors, and production constraints during the act of building the system.
This section documents the most common and instructive failure patterns encountered, along with how they were detected and contained.
Silent Assumption Drift
One of the most frequent failure modes involved AI-generated code making implicit assumptions about backend behavior, data shape, or orchestration guarantees that were no longer valid.
Examples included:
Assuming stable response schemas where backend contracts were still evolving
Treating placeholder values or mocks as authoritative
Inferring business logic that existed only in documentation comments, not in code
These failures were often syntactically correct and locally plausible, making them difficult to detect through output inspection alone.
Mitigation pattern
Backend responses were treated as the source of truth
Developers were required to log and inspect real responses before adapting mappings
Small, reviewable diffs made assumption drift visible during PR review
The goal was not to prevent incorrect assumptions entirely, but to surface them early and cheaply.
Over-Eager Automation
AI tools were occasionally effective at proposing end-to-end changes that spanned multiple files, concerns, or layers of the system. While efficient, this behaviour created risk by obscuring intent and expanding blast radius.
Typical manifestations:
Multi-file refactors bundled into a single change
Automation proposing to “clean up” code outside the stated task
Generated abstractions that reduced short-term friction but increased long-term opacity
These changes often passed basic validation but were difficult to reason about during review.
Mitigation pattern
Canary commits and enforced small diffs
Explicit rejection of “helpful” but unsolicited refactors
PR templates requiring contributors to state what was not changed
This constrained automation in favour of reviewability over throughput.
Transport and Orchestration Fragility
Real-time features introduced failure modes that were not visible at the level of individual API calls.
Observed issues included:
WebSocket disconnects masked as AI failures
SSE streams terminating without clear client-side signals
Retry loops amplifying load under degraded conditions
Without explicit logging, these failures could easily be misattributed to model behaviour rather than transport or orchestration layers.
Mitigation pattern
Connection lifecycle logging (connect, reconnect, exhaustion)
Distinguishing transport errors from tool invocation failures
Bounding retry behaviour to prevent cascading effects
This reframed “AI unreliability” as system unreliability, which could be debugged and addressed.
Validation Boundary Violations
AI-generated changes occasionally bypassed or weakened existing validation logic, particularly around form handling, input schemas, or authorization checks.
These failures were subtle because:
Generated code often mirrored existing patterns
Type checks passed
Happy-path behaviour appeared correct
The risk was not immediate failure, but erosion of safety boundaries over time.
Mitigation pattern
Mandatory pre-PR validation (lint, type checks, tests, builds)
Treating validation failures as workflow failures, not code failures
Review emphasis on boundary integrity rather than feature completion
Misuse Through Misinterpretation
A recurring misuse pattern was humans over-trusting AI-generated explanations of code they did not fully inspect.
This manifested as:
Accepting confident summaries without verifying behavior
Treating AI-generated comments as documentation
Skipping manual inspection when output “looked right”
This was not malicious misuse, but a predictable cognitive shortcut.
Mitigation pattern
Review norms that privileged observable behavior over explanation
Preference for logs, tests, and runtime inspection over narrative descriptions
Explicit cultural framing: AI suggestions are starting points, not conclusions
Summary: Failures as Signals, Not Exceptions
The failure modes observed during development were not edge cases. They were structural consequences of introducing probabilistic tools into a production workflow.
Rather than attempting to eliminate these failures, the development system was shaped to:
make failures observable
limit their blast radius
preserve human judgment at decision points
keep recovery cheap and reversible
This posture treated failure not as a breakdown, but as a primary design input for AI-assisted development workflows.
AI-Assisted Development Workflow
AI was integrated into the LyndaAI development process as a constrained collaborator, not an autonomous agent. The workflow was designed to extract speed and leverage from AI assistance while preserving reviewability, intent clarity, and human judgment at every decision boundary.
This section describes how AI tools were used day-to-day, and the constraints that shaped their effective use during MVP delivery.
Role of AI in the Development Loop
AI tools were primarily used to assist with:
incremental code generation and refactoring
scaffolding UI components and data mappings
drafting documentation and internal notes
summarizing changes or proposing next steps
They were explicitly not used to:
merge code automatically
bypass validation or review
make architectural decisions without human confirmation
infer backend behavior without inspection
This distinction was enforced culturally and mechanically.
Small Diffs as a First-Class Constraint
The workflow privileged small, reviewable diffs over maximal automation.
Key practices included:
breaking AI-assisted changes into narrow, task-scoped commits
rejecting multi-concern refactors, even when technically correct
preferring several small iterations over one comprehensive change
This constraint served two purposes:
It reduced the blast radius of AI-generated mistakes.
It preserved human ability to reason about intent during review.
Speed was gained through iteration, not through bundling.
Canary Commits and Progressive Trust
AI-assisted changes were often introduced as canary commits—minimal changes intended to validate assumptions rather than complete features.
Examples included:
adding instrumentation before modifying logic
introducing schema checks before expanding handlers
logging real backend responses prior to adapting UI mappings
Trust in an AI-assisted change was earned progressively, based on observed behaviour rather than confidence of explanation.
Validation as a Workflow Gate
Validation was treated as a workflow requirement, not a final safety net.
Before opening a pull request, contributors were expected to run:
linting and type checks
unit tests and Storybook builds
end-to-end tests where applicable
production builds
AI-generated changes that failed validation were treated as workflow failures, prompting either:
refinement of the AI prompt
decomposition of the task
or manual intervention
The goal was to surface incompatibilities early, when correction was cheap.
Review Discipline and Human Judgment
Pull request review remained the primary decision point.
Review practices emphasized:
understanding why a change was made, not just what changed
identifying hidden assumptions in AI-generated code
verifying boundary conditions and failure paths
explicitly noting uncertainty where behavior was not fully exercised
PR templates required contributors to state:
what was changed
what was tested
what was intentionally left untested or deferred
This made uncertainty explicit rather than implicit, reducing downstream surprise.
Treating AI as a Contributor, Not an Authority
Throughout development, AI was framed as:
a fast but fallible contributor
capable of proposing plausible code
incapable of validating correctness or intent on its own
This framing influenced both tool usage and team norms:
AI explanations were not accepted without corroboration
logs, tests, and runtime behavior were privileged over narrative summaries
responsibility for correctness always rested with a human reviewer
This posture reduced misuse without requiring rigid prohibitions.
Summary: Workflow Over Automation
The AI-assisted development workflow prioritized:
containment over autonomy
diagnosability over speed
iteration over completeness
judgment over delegation
Rather than attempting to eliminate human involvement, the workflow was designed to support human decision-making under uncertainty, acknowledging that AI assistance changes how software is built, not who is accountable for it.
Constraints, Limits, and Open Questions
This case study documents a development system designed to make AI-assisted work safer, more diagnosable, and more reviewable. It does not claim to eliminate uncertainty, automation risk, or coordination overhead. Several constraints remained fundamental throughout development.
What This System Could Not Do
Guarantee correctness of AI-generated changes
Validation, testing, and review reduced risk but did not eliminate it. Human judgment remained necessary to assess intent, edge cases, and long-term maintainability.
Remove coordination overhead entirely
AI assistance accelerated local tasks, but it did not replace the need for shared context, review discipline, or alignment across contributors.Generalize across all AI tasks or domains
The workflows and guardrails were tuned for building a production frontend with LLM-assisted development. They do not automatically transfer to all forms of automation or model-driven systems.Prevent all misuse by default
Cultural norms and mechanical constraints reduced misuse, but over-trust and assumption drift remained ongoing risks that required active attention.
Tradeoffs Accepted Intentionally
Several tradeoffs were accepted rather than optimized away:
Speed vs. reviewability
Small diffs and canary commits slowed some changes but preserved the ability to reason about intent and side effects.Flexibility vs. safety boundaries
Validation gates and explicit constraints limited creative freedom in favor of boundary integrity.Automation vs. accountability
AI was treated as an assistive contributor, not a decision-maker, to preserve clear ownership and responsibility.
These choices reflect a preference for containment and recovery over maximal automation.
Open Questions
This work surfaced unresolved questions that remain relevant beyond this system:
How should teams measure the quality of AI-assisted development, not just throughput?
Where should responsibility be assigned when AI-generated changes pass automated checks but fail in production?
How can evaluation surfaces evolve as AI tools become more deeply embedded in development workflows?
What signals best indicate when AI assistance is helping versus quietly increasing long-term risk?
These questions were not fully answered here. They are presented as ongoing design concerns, not solved problems.
Closing Note
The primary outcome of this work was not a perfected workflow, but a clearer understanding of how AI-assisted development changes the shape of software work. Building production systems that contain probabilistic behavior requires rethinking evaluation, review, and responsibility—not just adding tools.
This case study should be read as an exploration of those constraints, grounded in a real production context, rather than as a prescriptive model for automation.